



Why most AI support implementations fail (and how to get it right).
The most useful single number for B2B leaders evaluating an AI support rollout came out of MIT's NANDA initiative in 2025. The research, drawing on a review of more than 300 publicly disclosed AI initiatives, structured interviews, and senior-leader surveys, found that 95% of generative AI pilots fail to deliver measurable business return, despite the roughly $30–$40 billion enterprises had collectively spent on them.
Ninety-five percent. The instinct is to read that as a verdict on the technology. It isn't.
Below are the five most common failure modes in B2B support specifically, and the system requirements that prevent them.
Failure 1: Poor training data
Most teams point the AI at their existing knowledge base, mark the integration complete, and treat it as trained. It isn't. A static knowledge base reflects what the team thought to write down, not how customers actually phrase their problems, and not how the team's experts actually resolve them in the wild.
The result is an AI that is technically grounded in real documentation but practically incapable of meeting customers where they are. It answers the documented question; the customer asked a different question that resolves to the same documented answer; the AI doesn't make the connection; the conversation breaks. The team interprets this as the AI being "not ready" and pulls back. The training-data failure compounds: the system never sees the conversational distribution that would teach it to resolve correctly, because the team stopped feeding it those conversations.
Working systems treat training data as a continuous input, historical tickets, real customer language, the actual resolution paths the team's senior reps use, not as a one-time documentation upload.
Failure 2: No real ticket integration
This one is easy to spot from the outside. The AI lives in a chat widget on the marketing site or inside a help-center bubble. It cannot see the customer's account record. It does not know which tickets the customer has filed before. It has no awareness of plan tier, contract terms, recent product issues affecting that customer's region, or whether the customer is currently in a renewal window.
Every conversation starts from zero context. The customer has to re-explain who they are, what they're using, and what they tried before. Resolution becomes impossible without a human eventually pulling the context together, which means the AI hasn't actually resolved anything; it has added a tier above the support queue.
Customers leave the AI conversation more frustrated than they arrived, and the team's deflection metrics flatter a system that's actively damaging the experience.
Failure 3: No action capability
The AI can describe how to reset a password but cannot reset one. It can quote the refund policy but cannot issue a refund. It can explain the upgrade flow but cannot execute it. Every "resolution" terminates with the customer being told what to do next, or with the conversation being routed to a human to actually do it.
This is the most common architectural failure in the category. It produces an AI that performs well on demos and badly in production.

Failure 4: No escalation safety
The two failure shapes are opposite, and both common.
The first is over-confidence: the AI answers questions it shouldn't, hallucinates plausibly, and the customer accepts the answer because the system delivered it with conviction. The damage shows up days later when the customer realizes the answer was wrong.
The second is over-escalation: every ambiguous question routes to a human, the AI's contribution to the conversation becomes triage, and the team correctly concludes the system is producing more work than it removes.
The fix is calibrated handoff logic:
- Explicit confidence thresholds that vary by intent type and account tier.
- Explicit policy boundaries, anything touching contracts, refunds outside policy, sensitive account changes routes to a human by default.
- Explicit account-tier awareness, high-value accounts get human escalation by default, every time.
- Explicit handoff context, the human inheriting the conversation gets the full transcript, the customer's account state, and the AI's reasoning about why it escalated.
Without those, escalations damage CX even when they're the right call.
Failure 5: An AI that only answers, not resolves
This is the meta-failure underneath the previous four. A system designed to answer questions will optimize for plausible-sounding answers and report success on metrics that count interactions. A system designed to resolve issues will optimize for end-to-end customer outcome and report on metrics that count resolutions.
Most failed implementations are answer-focused systems sold as resolution-focused systems. The vendor demoed the answers. The customer's actual workflow needed resolutions. The gap between those two is where the 95% failure rate lives.
The architectural difference shows up everywhere, in how the AI is trained, what it's integrated with, what actions it can take, how it escalates.
What a working system requires
Three structural requirements separate the implementations that produce ROI from the ones that produce abandonment.

The pattern
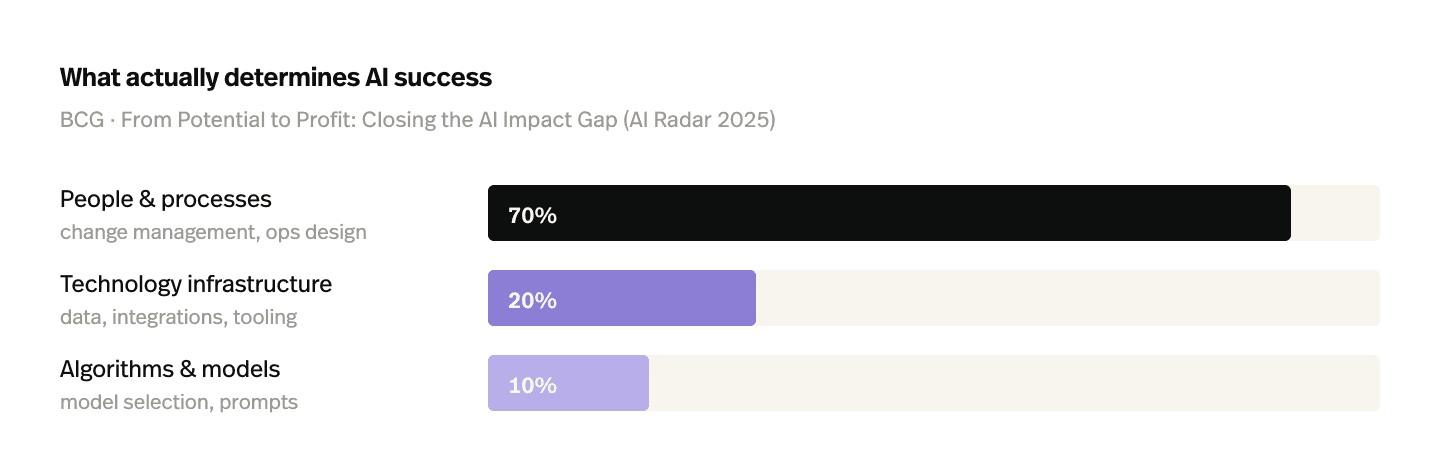
The implementations that succeed don't have better algorithms than the ones that fail. They have better operating models around the algorithms, better training discipline, real integrations, action capability, calibrated escalation, and a feedback loop that makes the system smarter every week. That's exactly the 70/20/10 split BCG's research described.
The fix for a stalled AI support implementation is almost never a vendor switch. It's an operating-model commitment to the work that the 70% covers. Teams that make that commitment are in the 5% that produce returns. Teams that don't are in the 95% that don't.
How Helply approaches the 70%
The architecture decisions we made, actions over answers, real ticket-system integration, calibrated escalation, ticket-level continuous improvement, were direct responses to the failure modes above. See how AI outcome works in Helply →
Sources

